进程/线程上下文切换会用掉你多少CPU?
进程是操作系统的伟大发明之一,对应用程序屏蔽了CPU调度、内存管理等硬件细节,而抽象出一个进程的概念,让应用程序专心于实现自己的业务逻辑既可。
而且在有限的CPU上可以“同时”进行许多个任务。但是它为用户带来方便的同时,也引入了一些额外的开销。如下图,在进程运行中间的时间里,虽然CPU也在忙于干活,但是却没有完成任何的用户工作,这就是进程机制带来的额外开销。
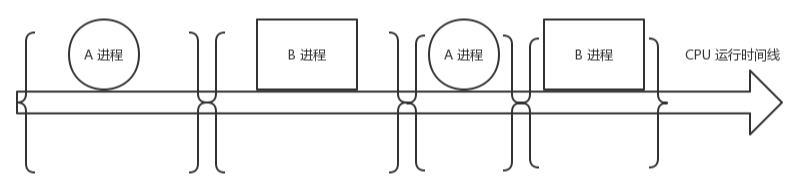
在进程A切换到进程B的过程中,先保存A进程的上下文,以便于等A恢复运行的时候,能够知道A进程的下一条指令是啥。
然后将要运行的B进程的上下文恢复到寄存器中。这个过程被称为上下文切换。
上下文切换开销在进程不多、切换不频繁的应用场景下问题不大。但是现在Linux操作系统被用到了高并发的网络程序后端服务器。在单机支持成千上万个用户请求的时候,这个开销就得拿出来说道说道了。因为用户进程在请求Redis、Mysql数据等网络IO阻塞掉的时候,或者在进程时间片到了,都会引发上下文切换。
进程上下文切换开销都有哪些
那么上下文切换的时候,CPU的开销都具体有哪些呢?开销分成两种,一种是
直接开销、一种是间接开销。直接开销就是在切换时,cpu必须做的事情,包括:
- 切换页表全局目录
- 切换内核态堆栈
- 切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- ip(instruction pointer):指向当前执行指令的下一条指令
- bp(base pointer): 用于存放执行中的函数对应的栈帧的栈底地址
- sp(stack poinger): 用于存放执行中的函数对应的栈帧的栈顶地址
- cr3:页目录基址寄存器,保存页目录表的物理地址
- ……
- 刷新TLB
- 系统调度器的代码执行
间接开销主要指的是虽然切换到一个新进程后,由于各种缓存并不热,速度运行会慢一些。
如果进程始终都在一个CPU上调度还好一些,如果跨CPU的话,之前热起来的TLB、L1、L2、L3因为运行的进程已经变了,所以以局部性原理cache起来的代码、数据也都没有用了,导致新进程穿透到内存的IO会变多。 其实我们上面的实验并没有很好地测量到这种情况,所以实际的上下文切换开销可能比3.5us要大。
协程究竟比线程能省多少开销?
为了避免频繁的上下文切换,还有一种异步非阻塞的开发模型。那就是用一个进程或线程去接收一大堆用户的请求,然后通过IO多路复用的方式来提高性能(进程或线程不阻塞,省去了上下文切换的开销)。Nginx和Node Js就是这种模型的典型代表产品。平心而论,从程序运行效率上来,这种模型最为机器友好,运行效率是最高的(比下面提到的协程开发模型要好)。所以Nginx已经取代了Apache成为了Web Server里的首选。但是这种编程模型的问题在于开发不友好,说白了就是过于机器化,离进程概念被抽象出来的初衷背道而驰。人类正常的线性思维被打乱,应用层开发们被逼得以非人类的思维去编写代码,代码调试也变得异常困难。
于是就有一些聪明的脑袋们继续在应用层又动起了主意,设计出了不需要进程/线程上下文切换的“线程”,协程。用协程去处理高并发的应用场景,既能够符合进程涉及的初衷,让开发者们用人类正常的线性的思维去处理自己的业务,也同样能够省去昂贵的进程/线程上下文切换的开销。因此可以说,协程就是Linux处理海量请求应用场景里的进程模型的一个很好的的补丁。
背景介绍完了,那么我想说的是,毕竟协程的封装虽然轻量,但是毕竟还是需要引入了一些额外的代价的。那么我们来看看这些额外的代价具体多小吧。
协程开销测试
- 协程切换CPU开销
测试过程是不断在协程之间让出CPU。核心代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20func cal() {
for i :=0 ; i<1000000 ;i++{
runtime.Gosched()
}
}
func main() {
runtime.GOMAXPROCS(1)
currentTime:=time.Now()
fmt.Println(currentTime)
go cal()
for i :=0 ; i<1000000 ;i++{
runtime.Gosched()
}
currentTime=time.Now()
fmt.Println(currentTime)
}编译运行
1
2
3
4
5# cd tests/test05/src/main/;
# go build
# ./main
2019-08-08 22:35:13.415197171 +0800 CST m=+0.000286059
2019-08-08 22:35:13.655035993 +0800 CST m=+0.240124923平均每次协程切换的开销是(655035993-415197171)/2000000=120ns。进程切换开销大约3.5us,大约是其的三十分之一。比系统调用的造成的开销还要低。
- 协程内存开销
- 在空间上,协程初始化创建的时候为其分配的栈有2KB。而线程栈要比这个数字大的多,可以通过ulimit 命令查看,一般都在几兆,作者的机器上是10M。如果对每个用户创建一个协程去处理,100万并发用户请求只需要2G内存就够了,而如果用线程模型则需要10T。
1 | # ulimit -a |
小结
协程由于是在用户态来完成上下文切换的,所以切换耗时只有区区100ns多一些,比进程切换要高30倍。单个协程需要的栈内存也足够小,只需要2KB。所以,近几年来协程大火,在互联网后端的高并发场景里大放光彩。
无论是空间还是时间性能都比进程(线程)好这么多,那么Linux为啥不把它在操作系统里实现了多好?操作系统为了实现实时性更好的目的,对一些优先级比较高的进程是会抢占其它进程的CPU的。而协程无法实现这一点,还得依赖于挡前使用CPU的协程主动释放,于操作系统的实现目的不相吻合。所以协程的高效是以牺牲可抢占性为代价的。
由于go的协程调用起来太方便了,所以一些go的程序员就很随意地go来go去。要知道go这条指令在切换到协程之前,得先把协程创建出来。而一次创建加上调度开销就涨到400ns,差不多相当于一次系统调用的耗时了。虽然协程很高效,但是也不要乱用,否则go祖师爷Rob Pike花大精力优化出来的性能,被你随意一go又给葬送掉了。

