纪录 mongo 的一些杂糅知识点
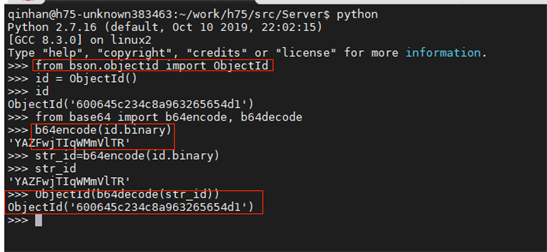
ObjectId
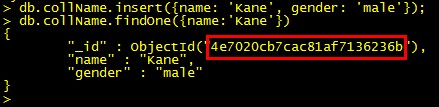
- 首先通过终端命令行,向mongodb的collection中插入一条不带“_id”的记录。然后,通过查询刚插入的数据,发现自动生成了一个objectId,4e7020cb7cac81af7136236b。具体操作如图1所示。
- “4e7020cb7cac81af7136236b”这个24位的字符串,虽然看起来很长,也很难理解,但实际上它是由一组十六进制的字符构成,每个字节两位的十六进制数字,总共用了12字节的存储空间。相比MYSQL int类型的4个字节,MongoDB确实多出了很多字节。不过按照现在的存储设备,多出来的字节应该不会成为什么瓶颈。不过MongoDB的这种设计,体现着空间换时间的思想。官网中对ObjectId的规范,如图2所示。

1) Time
时间戳。将刚才生成的objectid的前4位进行提取“4e7020cb”,然后按照十六进制转为十进制,变为“1315971275”,这个数字就是一个时间戳。通过时间戳的转换,就成了易看清的时间格式,如图3所示。

2) Machine
- 机器。接下来的三个字节就是“7cac81”,这三个字节是所在主机的唯一标识符,一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器hash值,确保在分布式中不造成冲突,这也就是在同一台机器生成的objectId中间的字符串都是一模一样的原因。
3) PID
- 进程ID。上面的Machine是为了确保在不同机器产生的objectId不冲突,而pid就是为了在同一台机器不同的mongodb进程产生了objectId不冲突,接下来的“af71”两位就是产生objectId的进程标识符。
4) INC
自增计数器。前面的九个字节是保证了一秒内不同机器不同进程生成objectId不冲突,这后面的三个字节“36236b”是一个自动增加的计数器,用来确保在同一秒内产生的objectId也不会发现冲突,允许256的3次方等于16777216条记录的唯一性。
总的来看,objectId的前4个字节时间戳,记录了文档创建的时间;接下来3个字节代表了所在主机的唯一标识符,确定了不同主机间产生不同的objectId;后2个字节的进程id,决定了在同一台机器下,不同mongodb进程产生不同的objectId;最后通过3个字节的自增计数器,确保同一秒内产生objectId的唯一性。ObjectId的这个主键生成策略,很好地解决了在分布式环境下高并发情况主键唯一性问题,值得学习借鉴。
附带一段有关于python中使用bson id的代码
可以利用base64编码将 objectid 转化成字符串,可以作为唯一id,某大厂自研引擎就是这样干的