C++ 中的 编译 & 连接 过程
预处理
- 任何以
#开头的都是预处理指令,当编译器接收到一个源文件时对它做的第一件事情就是处理所有的预处理指令 - 预处理指令发生在真正的编译之前
- eg :
- 我们常用的
#include<iostream>指令,就是将该文件中的所有内容 copy 到当前文件中 - define,if,ifdef,ifndef,pragma
- 我们常用的
编译
- 编译器将 c++ 代码转化成实际的机器码
- 所有的
.cpp文件都会被编译,而头文件则不会,only cpp file,头文件是通过include指令加入到 cpp 文件中 - 每个 cpp 文件也叫做 translation unity(编译单元),会一个一个的被单独编译,每个 cpp 文件会被编译成一个 object 文件(win扩展名为 .obj)
- 编译器会根据代码创建
abstract syntax tree来表达我们的代码,之后编译器将根据它来产生真正的机器码 - 说到底,编译器的工作就是将代码转化成
constant data(常数变量)orinstructions
链接
- 将编译过程产生的所有 object 文件拿到,并将他们联系起来
常见的链接错误
unresolved external symbol
- 连接器找不到它需要的东西
- 例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void Log(const char *message);
int Multiply(int a, int b)
{
Log(" In Multiply Func ");
return a * b;
}
int main()
{
std::cout << " In Main Func " << std::endl;
return 0;
} - 这个文件单独编译不会报错
- 如果没有实现Log函数,在链接的时候会报错,虽然
Multiply函数看起来像是死代码,但是它有可能被其他的地方用到,所以会发生错误 - 如果在
Multiply函数前面加上static关键字,就可以解决这个问题
重复的符号
- 相同的函数实现,一个函数在多个 cpp 文件中实现,在链接的阶段,连接器不知道去链接哪个
- 一般情况是不会写两遍函数实现,常见的情况就是在头文件中写来函数实现,然后有多个cpp文件都 include 了这个头文件
- include 的原理其实就是copy,这样就会有多个函数实现了,这也是我们将函数实现放到 cpp 文件中去的原因
#pragma once其实就是#ifndef _LOG_H,#define _LOG_H,#endif,防止一个头文件被多次 include1
2
3
4
5
6
void Log(const char* message)
{
std::cout << message << std::endl;
}
编译器简介

- 传统的编译器通常分为三个部分,前端(frontEnd),优化器(Optimizer)和后端(backEnd)
- Frontend:前端
- 词法分析、语法分析、语义分析、生成中间代码
- Optimizer:优化器
- 中间代码优化
- Backend:后端
- 生成机器码
编译器分类
GCC
- GCC(GNU Compiler Collection,GNU编译器套装),是一套由 GNU 开发的编程语言编译器。它是一套以 GPL 及 LGPL 许可证所发行的自由软件,也是 GNU计划的关键部分,亦是自由的类Unix及苹果电脑 Mac OS X 操作系统的标准编译器。
- GCC 原名为 GNU C 语言编译器,因为它原本只能处理 C语言。GCC 很快地扩展,变得可处理 C++。之后也变得可处理 Fortran、Pascal、Objective-C、Java, 以及 Ada与其他语言。
LLVM
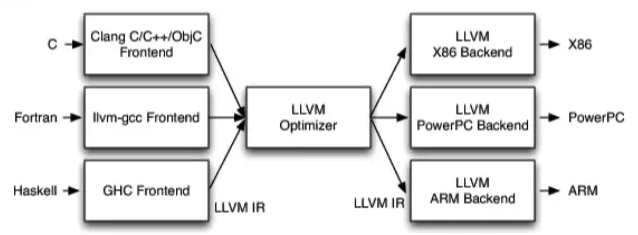
- 不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
- 如果需要支持一种新的编程语言,那么只需要实现一个新的前端
- 如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
- 优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
- 相比之下,GCC的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就 变得特别困难
- LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
Clang
LLVM项目的一个子项目,基于LLVM架构的C/C++/Objective-C编译器前端。
相比于GCC,Clang具有如下优点
- 编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
- 占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
- 模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
- 诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
- 设计清晰简单,容易理解,易于扩展增强
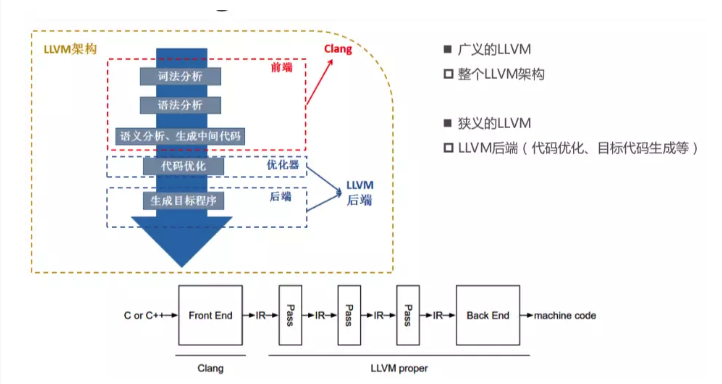
LLVM整体架构,前端用的是clang,广义的LLVM是指整个LLVM架构,一般狭义的LLVM指的是LLVM后端(包含代码优化和目标代码生成)。
源代码(c/c++)经过clang–> 中间代码(经过一系列的优化,优化用的是Pass) –> 机器码

