二叉树是什么就不用介绍了!
本文给大家分享的是常见的三种二叉树:完全二叉树、平衡二叉树、二叉查找(搜索)树
本文也是为以后的 红黑树,B树,B+树 做准备的
完全二叉树
完全二叉树是一种特殊的二叉树,满足以下要求:
- 所有叶子节点都出现在 k 或者 k-1 层,而且从 1 到 k-1 层必须达到最大节点数;
- 第 k 层可以不是满的,但是第 k 层的所有节点必须集中在最左边。
- 需要注意的是不要把完全二叉树和“满二叉树”搞混了,完全二叉树不要求所有树都有左右子树,但它要求:
- 任何一个节点不能只有右子树没有左子树
- 叶子节点出现在最后一层或者倒数第二层,不能再往上
用一张图对比下“完全二叉树”和“满二叉树”:
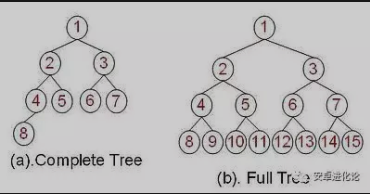
当我们用数组实现一个完全二叉树时,叶子节点可以按从上到下、从左到右的顺序依次添加到数组中,然后知道一个节点的位置,就可以轻松地算出它的父节点、孩子节点的位置。
以上面图中完全二叉树为例,标号为 2 的节点,它在数组中的位置也是 2,它的父节点就是 (k/2 = 1),它的孩子节点分别是 (2k=4) 和 (2k+1=5),别的节点也是类似。
完全二叉树使用场景:
- 根据前面的学习,我们了解到完全二叉树的特点是:“叶子节点的位置比较规律”。因此在对数据进行排序或者查找时可以用到它,比如堆排序就使用了它。
平衡二叉树
二叉树的提出其实主要就是为了提高查找效率,比如我们常用的 HashMap 在处理哈希冲突严重时,拉链过长导致查找效率降低,就引入了红黑树。
我们知道,二分查找可以缩短查找的时间,但是它要求 查找的数据必须是有序的。每次查找、操作时都要维护一个有序的数据集,于是有了二叉查找树这个概念。
二叉查找树(又叫二叉排序树),它是具有下列性质的二叉树:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
- 左、右子树也分别为二叉排序树。
如下图所示:
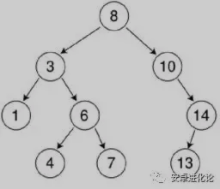
也就是说,二叉查找树中,左子树都比节点小,右子树都比节点大,递归定义。
根据二叉排序树这个特点我们可以知道:二叉排序树的中序遍历一定是从小到大的。
比如上图,中序遍历结果是:
1 3 4 6 7 8 10 13 14
二叉排序树的性能
在最好的情况下,二叉排序树的查找效率比较高,是 O(logn),其访问性能近似于折半查找;
但最差时候会是 O(n),比如插入的元素是有序的,生成的二叉排序树就是一个链表,这种情况下,需要遍历全部元素才行(见下图 b)。
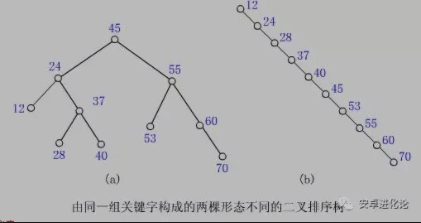
如果我们可以保证二叉排序树不出现上面提到的极端情况(插入的元素是有序的,导致变成一个链表),就可以保证很高的效率了。
但这在插入有序的元素时不太好控制,按二叉排序树的定义,我们无法判断当前的树是否需要调整。
因此就要用到平衡二叉树(AVL 树)了。
二叉查找(搜索)树
平衡二叉树的提出就是为了保证树不至于太倾斜,尽量保证两边平衡。因此它的定义如下:
- 平衡二叉树要么是一棵空树
- 要么保证左右子树的高度之差不大于 1
- 子树也必须是一颗平衡二叉树
也就是说,树的两个左子树的高度差别不会太大。
那我们接着看前面的极端情况的二叉排序树,现在用它来构造一棵平衡二叉树。
以 12 为根节点,当添加 24 为它的右子树后,根节点的左右子树高度差为 1,这时还算平衡,这时再添加一个元素 28:
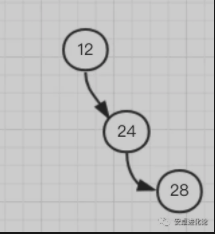
这时根节点 12 觉得不平衡了,我左孩子一个都没有,右边都有俩了,超过了之前说的最大为 1,不行,给我调整!
于是我们就需要调整当前的树结构,让它进行旋转。
因为最后一个节点加到了右子树的右子树,就要想办法给右子树的左子树加点料,因此需要逆时针旋转,将 24 变成根节点,12 右旋成 24 的左子树,就变成了这样(有点丑哈哈):
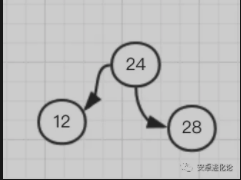
- 这时又恢复了平衡,再添加 37 到 28 的右子树,还算平衡:
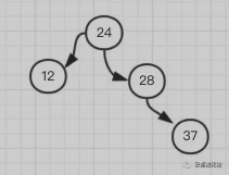
- 这时如果再添加一个 30,它就需要在 37 的左子树:
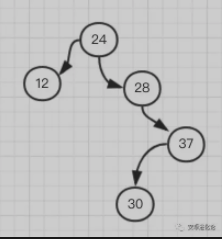
- 这时我们可以看到这个树又不平衡了,以 24 为根节点的树,明显右边太重,左边太稀,想要保持平衡就 24 得让位给 28,然后变成这样:
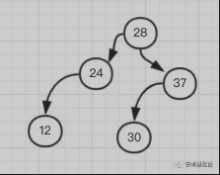
丑了点,但的确保持了平衡。
依次类推,平衡二叉树在添加和删除时需要进行旋转保持整个树的平衡,内部做了这么复杂的工作后,我们在使用它时,插入、查找的时间复杂度都是 O(logn),性能已经相当好了。
下面使用go实现一个二叉查找树
要实现一个二叉搜索树, 我们需要实现节点的插入和删除,要实现节点的查找(搜索),要实现前序遍历、中序遍历和后序遍历,要实现最大节点和最小节点的查找。
下面就让我们实现这个二叉搜索树。
定义基本数据结构
常规地,我们定义节点的类型,每个节点包含它的值以及左右节点。因为目前Go泛型还没有发布,所以这里我们实现一个元素为int类型的具体的二叉搜索树,等泛型实现后可以改成抽象的二叉搜索树。
树只要包含根节点可以了。
1
2
3
4
5
6
7
8
9
10// Node 定义节点.
type Node struct {
value int // 因为目前Go的泛型还没有发布,所以我们这里以一个int具体类型为例
left *Node // 左子节点
right *Node // 右子节点
}
// BST 是一个节点的值为int类型的二叉搜索树.
type BST struct {
root *Node
}数据结构有了,接下来就是实现各个方法。
搜索
- 检查一个节点是否存在比较简单,因为二叉搜索树是有序的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16func (this *BST) Search(value int) bool {
return search(this.root, value)
}
func search(n *Node, value int) bool {
if n == nil {
return false
}
if value < n.value {
return search(n.left, value)
}
if value > n.value {
return search(n.right, value)
}
return true
}
最大值 & 最小值
1 |
|
插入和删除
既然是一棵树,就需要增加节点用来构造树,大部分情况下也需要删除节点。
增加节点的时候,需要判断应该往左边子树上添加,还是往右边子树上添加。天然地,既然二叉搜索树是一个有序的,那么我们就可以进行比较,然后递归的实现。
1 | func (this *BST) Insert(value int) { |
遍历
- 可以实现先序遍历、中序遍历和后序遍历,先中后指的是根节点相对子节点的处理顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22func (this *BST) PreOrderTraverse(f func(int)) {
preOrderTraverse(this.root, f)
}
func preOrderTraverse(n *Node, f func(int)) {
if n != nil {
f(n.value) // 前
preOrderTraverse(n.left, f)
preOrderTraverse(n.right, f)
}
}
// PostOrderTraverse 后序遍历
func (this *BST) PostOrderTraverse(f func(int)) {
postOrderTraverse(this.root, f)
}
func postOrderTraverse(n *Node, f func(int)) {
if n != nil {
postOrderTraverse(n.left, f)
postOrderTraverse(n.right, f)
f(n.value) // 后
}
}

